




AIチャットボットと向き合う時、私たちはつい「自分とAIだけの閉じた空間」だと錯覚してしまいがちです。しかし、過去にChatGPTやGensparkで起きた「会話履歴の検索エンジン露出」という事象は、その認識がテクノロジーの実態といかに乖離しているかを浮き彫りにしました。
今回は、便利さの裏側にある「データの流れ」と、私たちが身につけるべき新しいデータリテラシーについて、設計思想の視点から解説します。
1. AIとの会話は「日記」ではなく「公開前のブログ」である
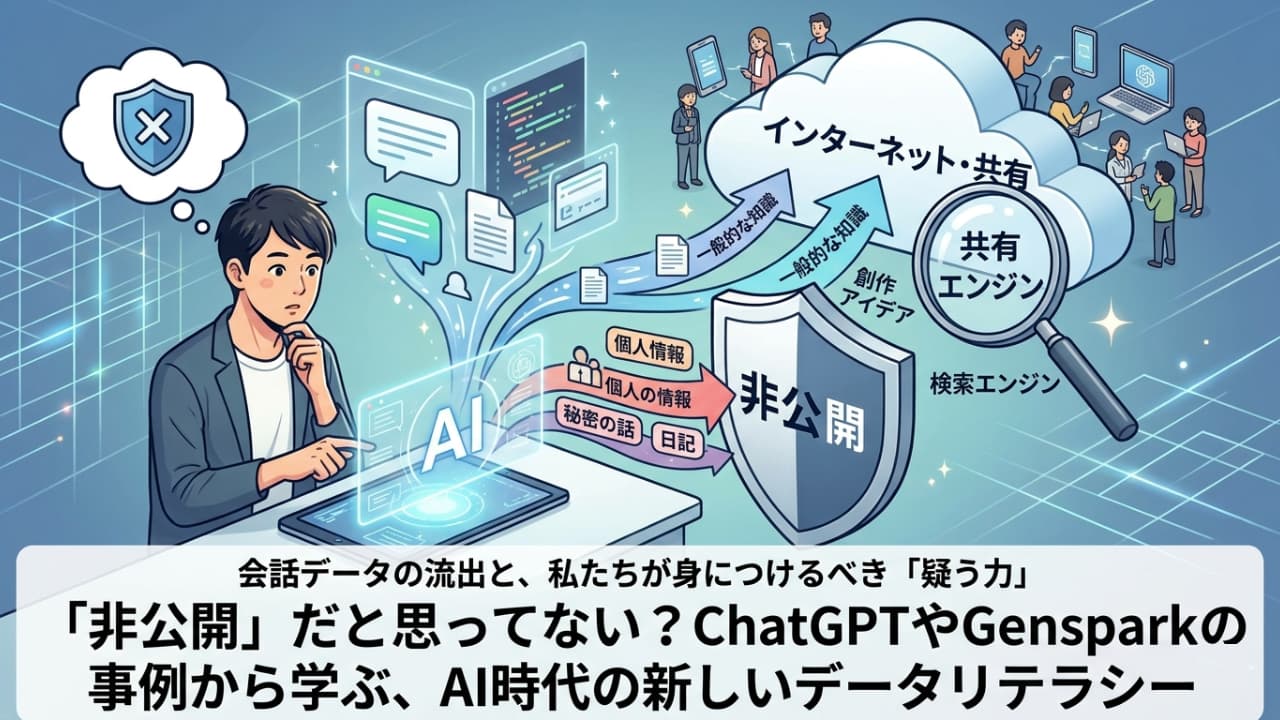
多くのユーザーは、AIとのチャットを鍵付きの日記帳のように感じています。しかし、技術的な実態は「インターネットにつながったサーバー上にあるデータベースへの書き込み」です。
ChatGPTで起きた事例では、ユーザーが「会話を共有する」というボタンを押した瞬間、そのデータは「特定のURLを知る人がアクセスできるWEBページ」へと姿を変えました。そして、そのURLをGoogleのクローラー(巡回プログラム)が見つけたことで、検索結果に表示されることになったのです。
つまり、AIに入力したデータは、私たちが意図したかどうかに関わらず、常に「公開される可能性を秘めた状態」にあると言えます。
2. なぜ「意図しない公開」が起きるのか?設計思想(UX)の罠
Gensparkの事例では、さらに興味深い問題が提起されました。初期のGensparkでは、AIが生成したまとめページ(Sparkpages)が、デフォルトで外部検索エンジンからアクセス可能な設定になっていたのです。
これは、運営側が「ユーザーが得た知見を広く世界と共有し、プラットフォームを成長させたい」という「共有(シェア)」を優先した設計思想を持っていたためと考えられます。
-
ユーザーの認識:個人的な調べ物をしている(プライベート)
-
プラットフォームの設計:良い情報はみんなで共有しよう(パブリック)
この認識のズレこそが、意図しない情報露出を生む最大の要因です。私たちはサービスを利用する際、そのツールが「プライバシー優先(Privacy by Design)」で設計されているか、それとも「共有優先」で設計されているかを見極める必要があります。
3. 私たちが身につけるべき「AIデータリテラシー」とは
これからのAI時代において、ただツールを使えるだけでは不十分です。自分の身を守り、テクノロジーと上手く付き合うための新しいデータリテラシーが必要です。
サービスごとの「公開レベル」を把握する
新しいAIサービスに触れる際は、まず設定画面を確認しましょう。特に「共有(Share)」「公開(Public)」「学習への利用(Training/Data Improvement)」に関する項目が、デフォルトでどうなっているかを確認する癖をつけることが重要です。
「入力データ」をレイヤー分けする
AIに入力する情報を、以下の3つのレイヤーに分けて管理することを推奨します。
-
レイヤー1(完全公開OK):一般的な知識の検索、プログラミングのコード生成(機密情報なし)、創作活動のアイデア出しなど。
-
レイヤー2(社内・チーム内公開OK):議事録の要約、プロジェクトのブレストなど。※ただし、社内規定で許可されたAIツールに限る。
-
レイヤー3(完全非公開):顧客の個人情報、未発表の機密プロジェクト、個人的すぎる悩み、パスワードなど。
レイヤー3の情報は、いかなるAIツールにも入力しない、というのが現時点での最も安全な最適解です。


4. 結論:AIリテラシーは「疑う力」から始まる
ChatGPTやGensparkの事例は、AIがまだ発展途上のテクノロジーであり、その運営ルールや技術仕様が常に変化し続けていることを教えてくれました。
「この画面は自分しか見ていないはず」という直感を疑い、データがどこへ行き、どのように処理される可能性があるのかを想像する力。それこそが、AIという強力なパートナーを安全に使いこなすための、これからの必修科目です。




